Iron: Private Inference on Transformers
Abstract
一种基于 Transformer 的隐私推理框架,提供了一套面向矩阵乘法和非线性运算的新型安全协议。第一,提出针对于同态加密下矩阵乘法的一种新型紧凑打包,这种设计减少了 倍通信开销。第二,对于 Softmax、GELU、LayerNorm 提出了优化。实现表明,Iron achieves 3 ∼ 14× less communication and 3 ∼ 11× less runtime compared to the prior art.所要解决的问题:
- 服务端不希望自己的模型权重发送给客户端,避免模型被盗取。
- 客户端不希望自己的隐私数据泄露给服务端。
- 能否有这样一种协议,使客户端得到计算结果 ,同时双方都不泄露各自的数据。
- 针对于线性层的矩阵乘法问题,Transformer-based model 使用了大量高维度的矩阵乘法,而不是被更广泛研究的矩阵向量乘法,两者并不互通。
- 针对于非线性层问题,Transformer-based model 使用的数学运算对于加密场景(尤其是非线性函数)并不友好。
Knowledge
2PC
在 “互不信任” 且 “不泄露私有数据” 的前提下,实现 的协同计算。- 安全性底线:服务器 看不见用户的输入,客户端 也拿不到服务器的模型权重。
- 原理:将原始数据 物理拆碎,满足 。
- 分配:
- (随机数):发送给服务器。
- (差值份额):保留在客户端。
AES
在隐私计算中,同态加密被定义为一个四元组算法 :- KeyGen (密钥生成):产生一对非对称密钥。
- 公钥 ():公开的“加密锁”,任何人均可用其将明文转化为密文。
- 私钥 ():私有的“解密匙”,仅数据所有者持有,用于还原明文。
- Enc (加密):映射过程 。将明文多项式编码并隐藏。
- Dec (解密):逆映射过程 。利用私钥将密文多项式还原。
- Eval (同态求值):核心精髓。在无需解密的前提下,对密文进行算术运算。
- 加法同态:
- 标量乘法同态:
- 噪声积聚 (Noise Growth):每次执行 (尤其是乘法运算)时,密文中的随机噪声会呈指数级或线性增长。
- 解密上限:一旦噪声超过了方案设定的临界阈值,密文将发生“雪崩效应”,导致解密后的数据彻底失效。
- 自举 (Bootstrapping):这是消除噪声的“核武器”。它通过在密文状态下运行解密电路,将高噪声密文刷新为低噪声密文。
OT
1. 标准 选 1 不经意传输 ()
这是隐私计算中的“盲选”原语,确保交互过程的双向匿名性。-
角色与输入:
- 发送者 (Sender):持有 个消息 。
- 接收者 (Receiver):持有一个私有索引 。
-
隐私保证 (Security):
- 发送者侧:完全不知道接收者选择了哪一个消息( 对发送者不可见)。
- 接收者侧:只能获得自己选择的 ,对其他 个消息一无所知(其余消息对接收者不可见)。
2. Iron 中的高效变体:相关 OT ()
为了压榨推理性能,Iron 大量使用了结构性更强的相关 OT。它的精妙之处在于将 “逻辑选择” 直接转化为了 “代数关系”。- 角色与输入:
- 发送者 (Sender):输入一个相关值 (通常是权重或中间计算值)。
- 接收者 (Receiver):输入一个选择位 (通常是份额的符号位或逻辑标志)。
- 协议输出 (Outputs):
- 发送者得到:一个随机数 。
- 接收者得到:。
Overview
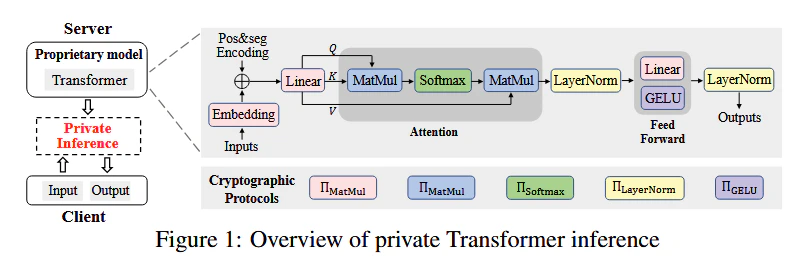
1. 注意力层 (Attention Layer)
A. 生成 (份额 权重)
以 Query 矩阵为例:- 本地项:。由于服务器 既有权重又有自己的那份碎片,它可以直接在本地算,无需任何通信。
- 协议项:只有针对客户端份额 的部分才需要动用同态加密。
B. 计算分数 (份额 份额)
这是两个碎片之间的乘法,根据分配律拆解为四项:- 见解:通过这种拆分,原本需要 4 次加密乘法的任务,被削减为 2 次,剩下的 2 次变成了免费的本地矩阵运算。
Solution
Protocol for Matrix Multiplication
Iron 的思路:- 紧凑打包(Compact Packing):将矩阵元素平铺在多项式的系数里。
- 维度并行:利用 三维窗口,同时在多项式内完成多个内积运算。
- 混合计算:利用秘密共享特性,将计算拆分为“本地项”与“协议项”,减少密文运算量。
- (右编码):客户端 将矩阵 的元素按照特定步长填入多项式系数。
- (左编码):服务器 将矩阵 进行旋转并编码。
- 按照上述公式 提取出数值。
- 由于 是 随机生成的掩码, 提取出的值就是

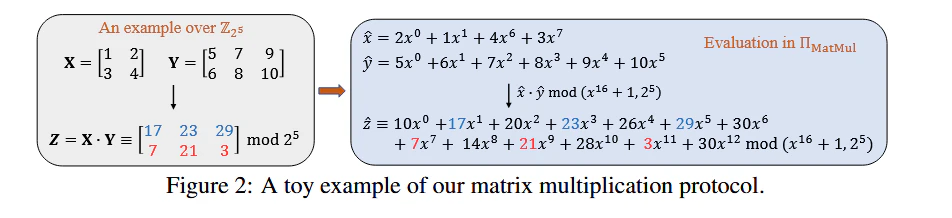
Protocols for Non-linear Functions

Softmax
Softmax 的标准公式为 。为了防止指数爆炸,Iron 采用如下形式: 第一步:安全寻最()- 动作: 协作通过二叉树约减协议找出向量 中的最大值。
- 目的:通过计算 ,确保后续指数运算的输入始终 。
- 密码学原语:使用之前提到的 (比较)和 。
- 动作:计算 。
- 技术见解:计算正指数 在有限域内极易溢出。Iron 专门设计了 (Negative Exponential) 协议,通过多项式近似或查表法(LUT)在密文状态下高效计算负指数。
- 结果:得到每个元素的指数份额。
- 动作:先在本地累加所有指数份额(线性运算,无需通信),然后调用 (Reciprocal) 协议计算总和的倒数:。
- 难点:倒数运算在定点数(Fix)环境下对精度极其敏感,通常需要通过牛顿迭代法或专门的 2PC 倒数协议完成。
- 动作:将“倒数份额”与“各元素的指数份额”相乘。
- 公式:。
- 原语:调用 完成最后这一步跨份额的乘法。

GELU
为了在 2PC 环境下计算,GELU 被近似表达为以下公式: 高阶项合成(三次幂计算): Iron 并不直接实现 ,而是利用 协议进行复用: 其中 。
LayerNorm
LayerNorm 的标准公式为: 步骤 I:离差平方的并行计算 (算 )-
计算均值 (本地完成):
由于 是线性运算,且 (维度)是公开常数。
- 在本地计算 。
- 在本地计算 。
- 优势:此步零通信。
- 计算离差 (本地完成): 双方本地执行减法,得到 。
-
计算平方项(协作完成):
为了得到 ,双方必须针对每个维度 调用一次 。
- 逻辑:这是一个秘密份额自乘的过程,需要处理 中的交叉项 。
- 输入:双方在本地对步骤 I 的结果求和,得到方差的原始份额 。
- 核心动作:调用 (Root Inverse Square) 协议。
- 实现原理:
- 范围归一化:将输入缩放到特定区间。
- 多项式近似:利用二阶或三阶多项式(如 )来逼近 函数。
- 计算:多项式的计算过程依然通过 来完成。
- 输出:得到 的秘密份额。
- 动作:双方针对每个维度 ,调用 。
- 输入项: 和 。
- 输出:产生最终结果 。
